什么是 Apache Cassandra?
Cassandra 是一个 NoSQL 分布式数据库。根据设计,NoSQL 数据库是轻量级、开源、非关系型且高度分布式的。其优势包括水平可扩展性、分布式架构以及灵活的模式定义方法。
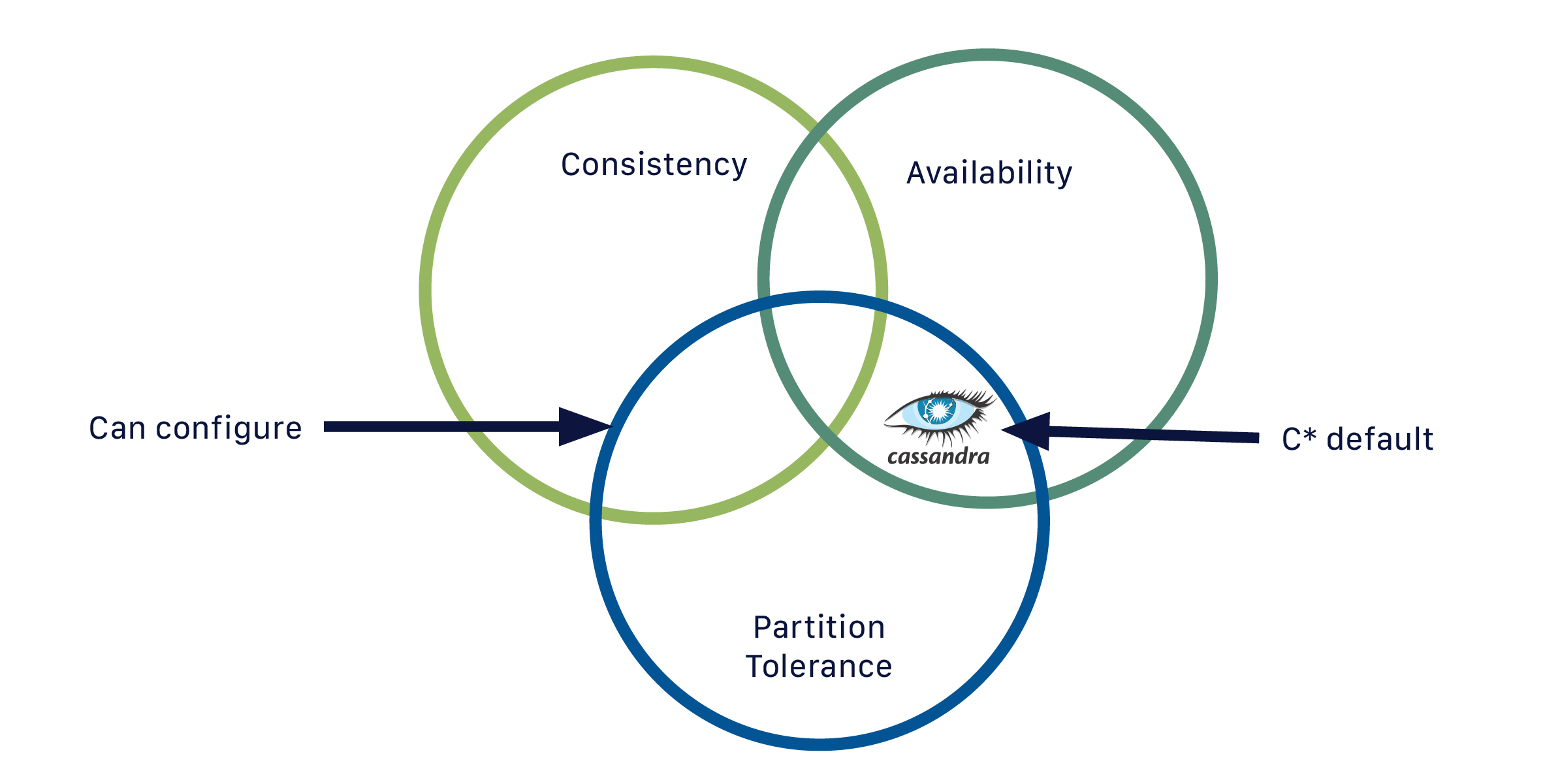
NoSQL 数据库能够快速、灵活地组织和分析海量、异构的数据类型。随着大数据的出现以及云中数据库快速扩展的需求,这一点在近年来变得越来越重要。Cassandra 是众多 NoSQL 数据库中的一种,它解决了以前数据管理技术(如 SQL 数据库)的限制。
分布式带来强大功能和弹性
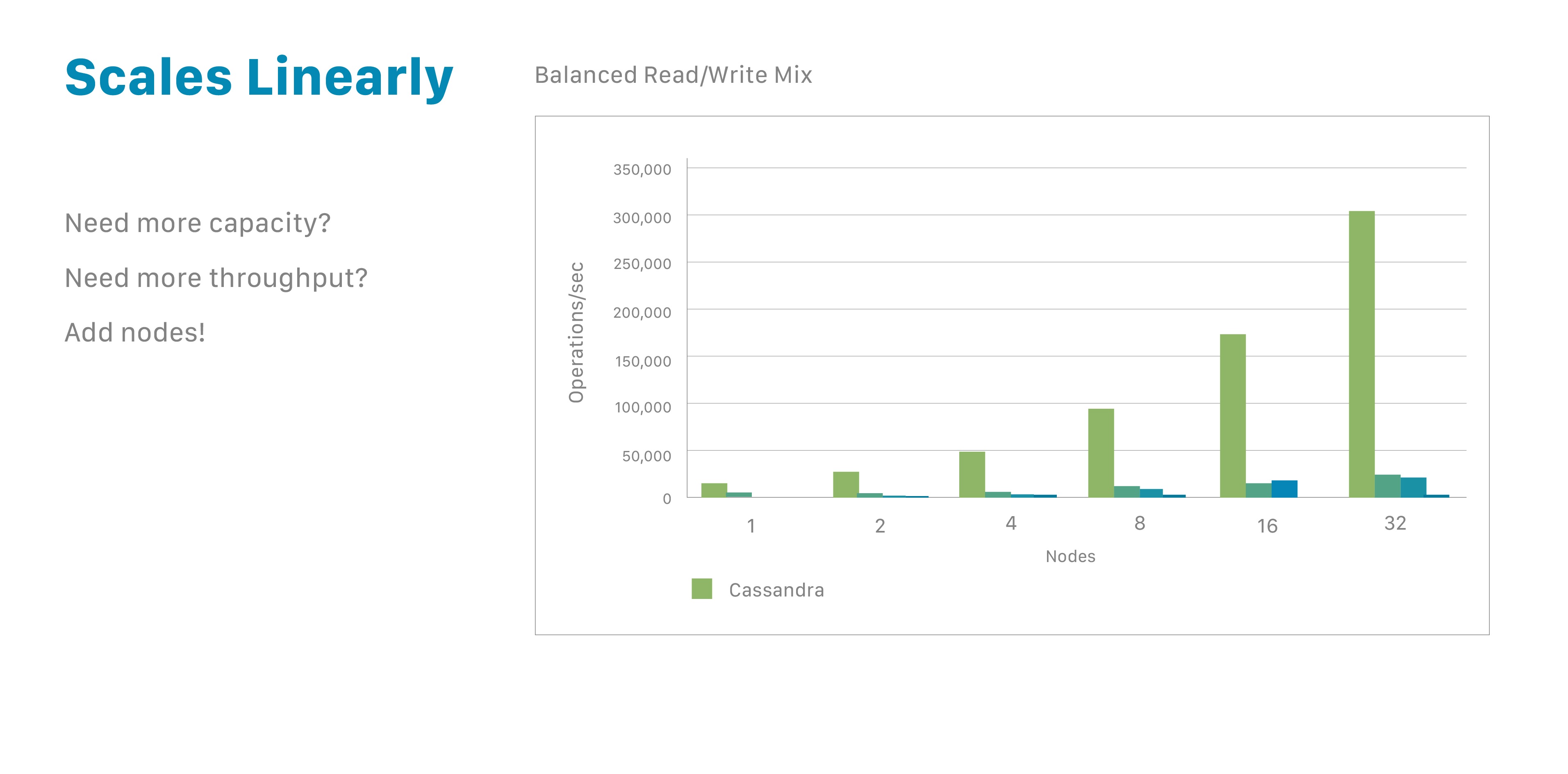
 Cassandra 的一个重要属性是其数据库是分布式的。这带来了技术和业务上的优势。Cassandra 数据库在应用程序承受高压力时可以轻松扩展,并且分布式还可以防止任何给定数据中心的硬件故障导致数据丢失。分布式架构还带来了技术上的强大功能;例如,开发人员可以独立调整读查询或写查询的吞吐量。
Cassandra 的一个重要属性是其数据库是分布式的。这带来了技术和业务上的优势。Cassandra 数据库在应用程序承受高压力时可以轻松扩展,并且分布式还可以防止任何给定数据中心的硬件故障导致数据丢失。分布式架构还带来了技术上的强大功能;例如,开发人员可以独立调整读查询或写查询的吞吐量。
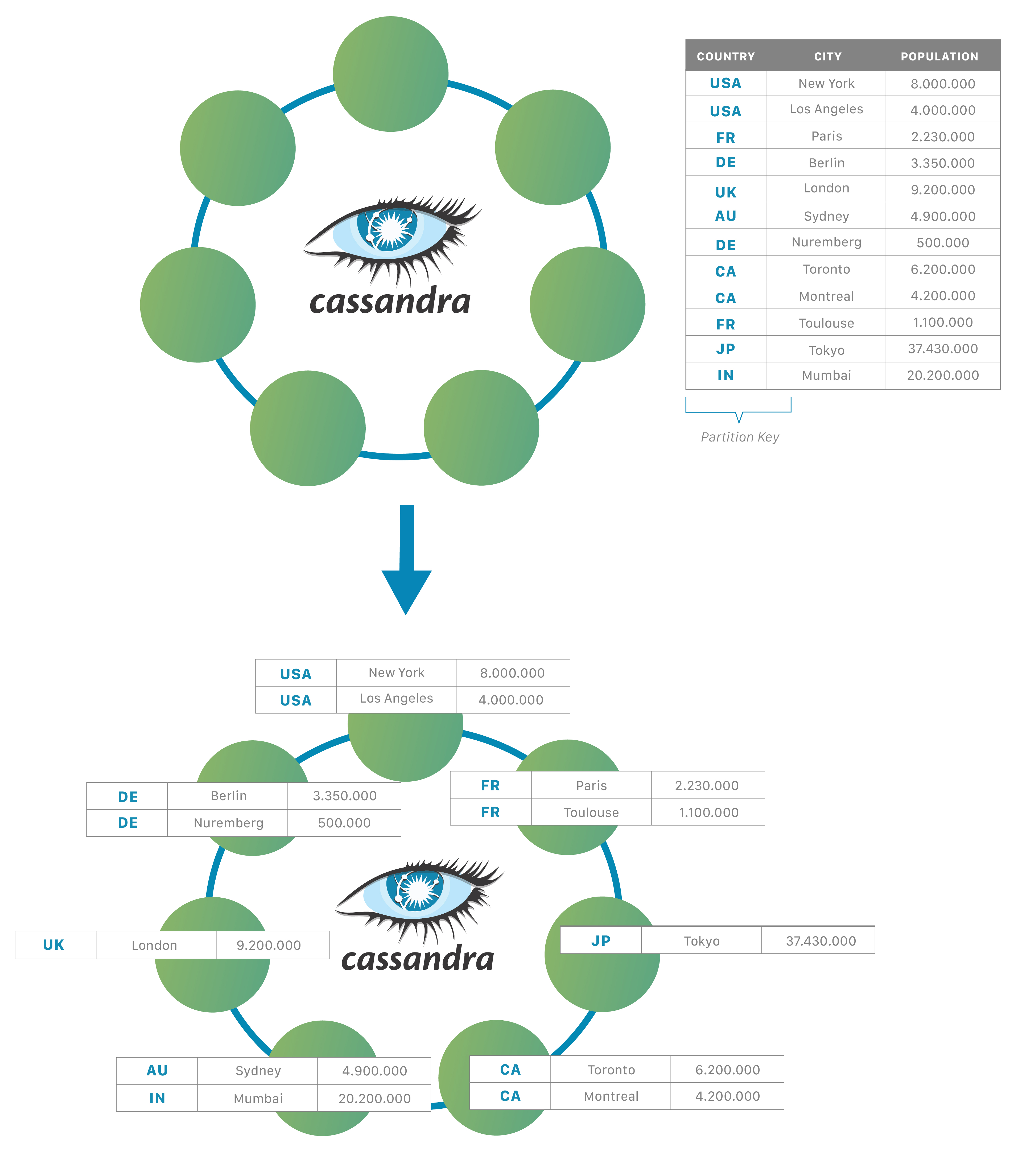
“分布式”意味着 Cassandra 可以运行在多台机器上,同时对用户来说就像一个统一的整体。虽然将 Cassandra 作为单个节点运行意义不大,但这样做非常有助于帮助你了解它的工作原理。但要充分利用 Cassandra,你应该在多台机器上运行它。
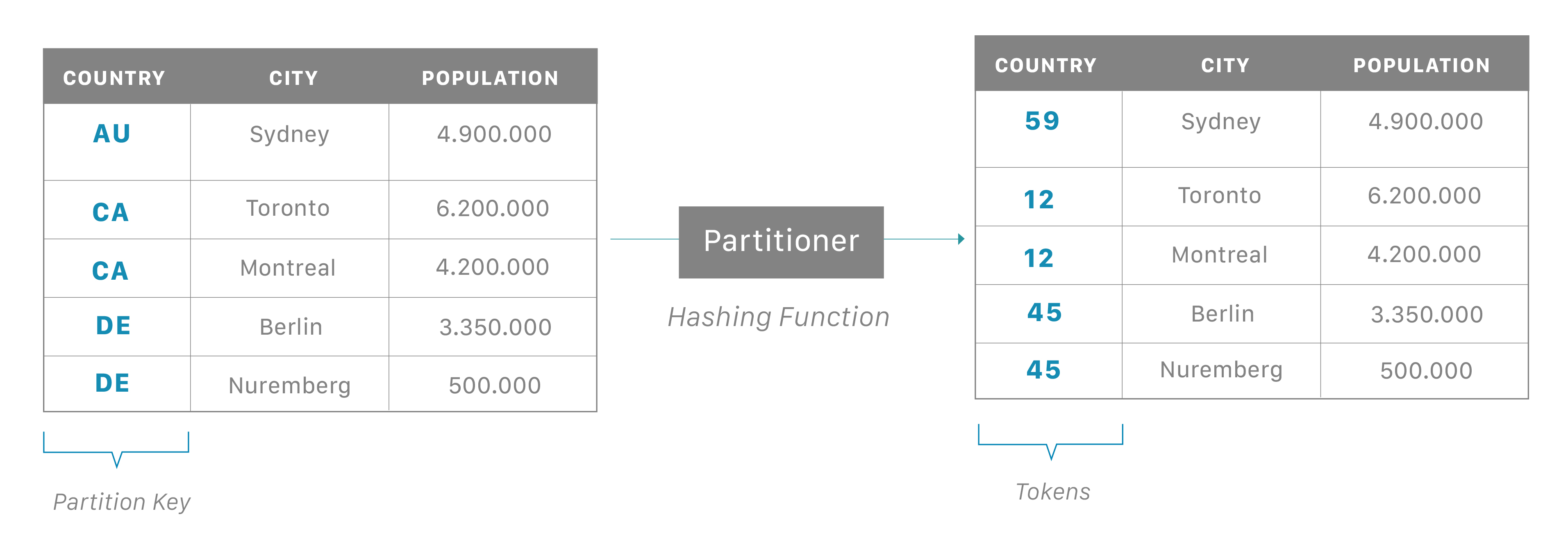
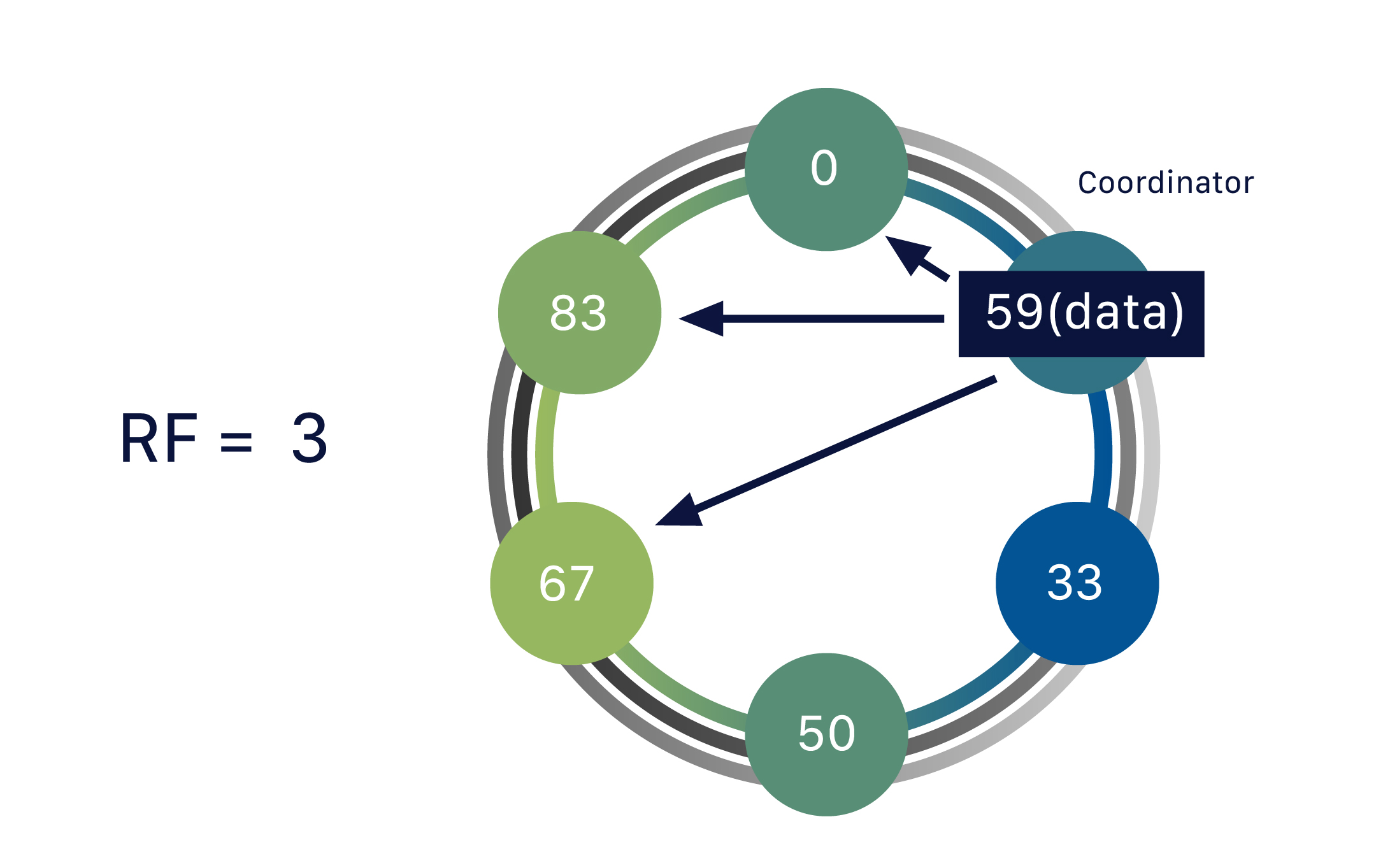
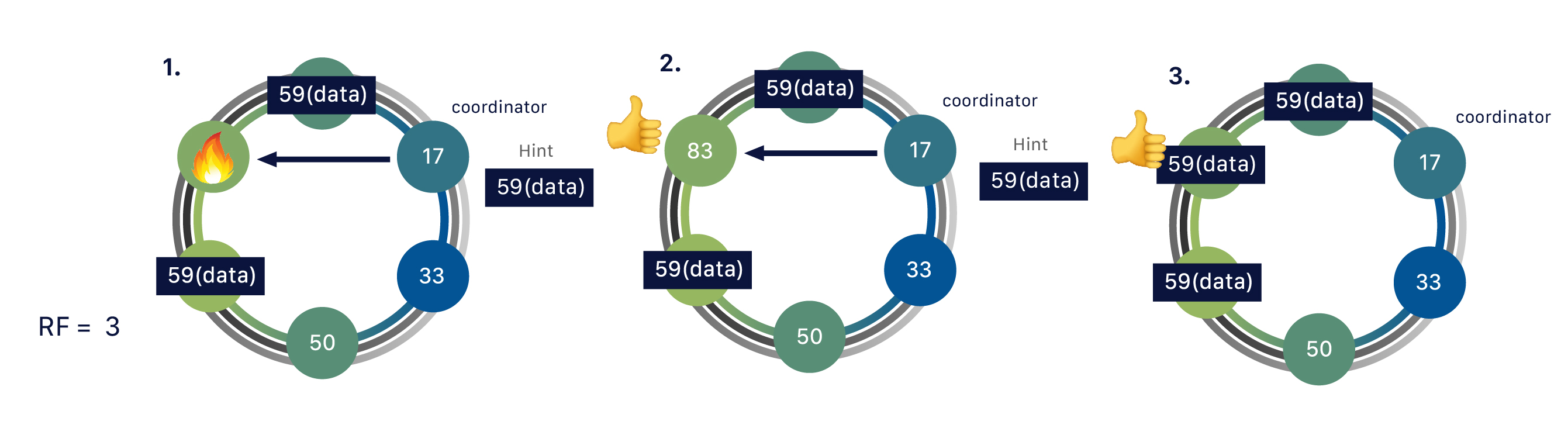
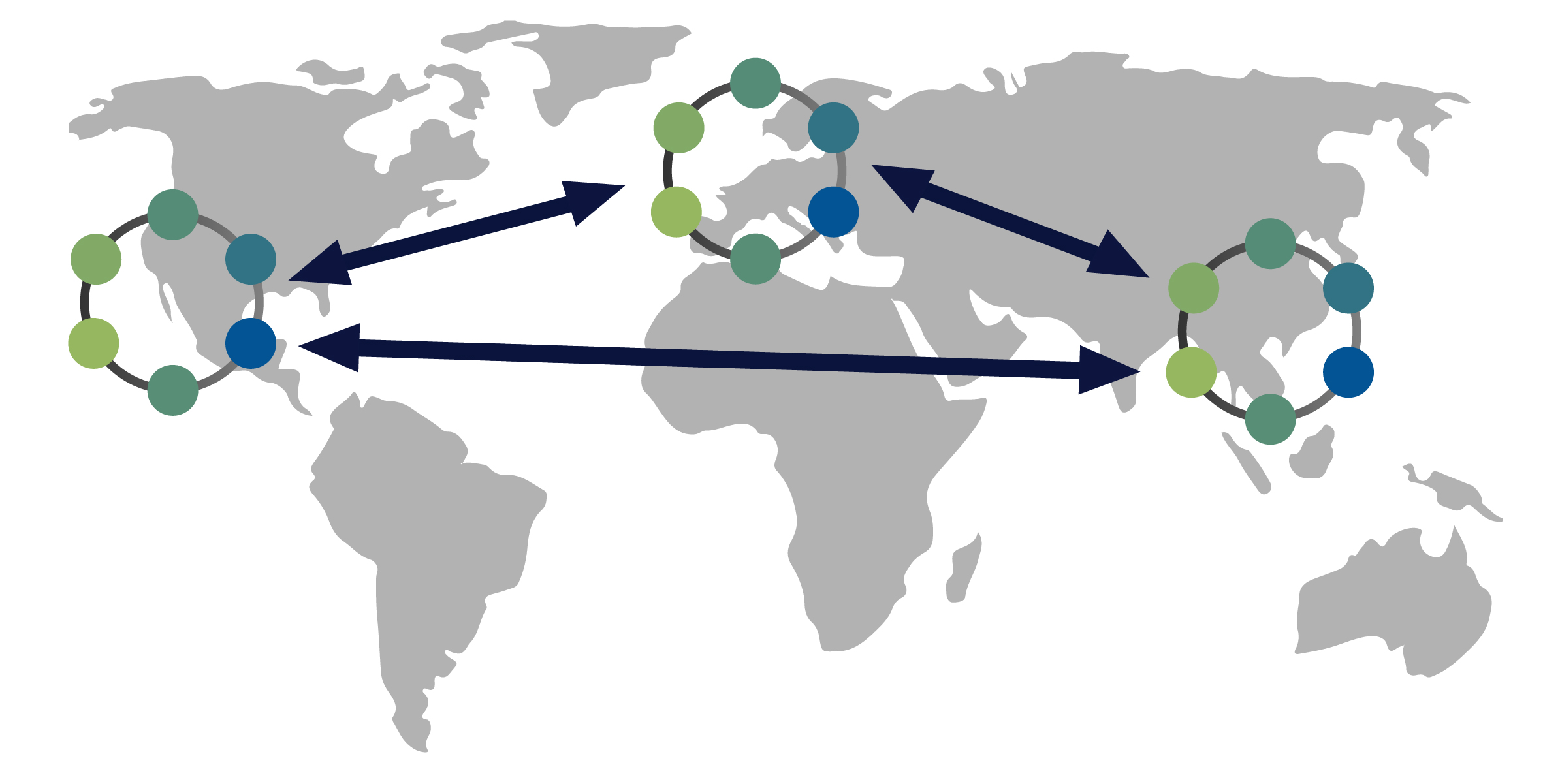
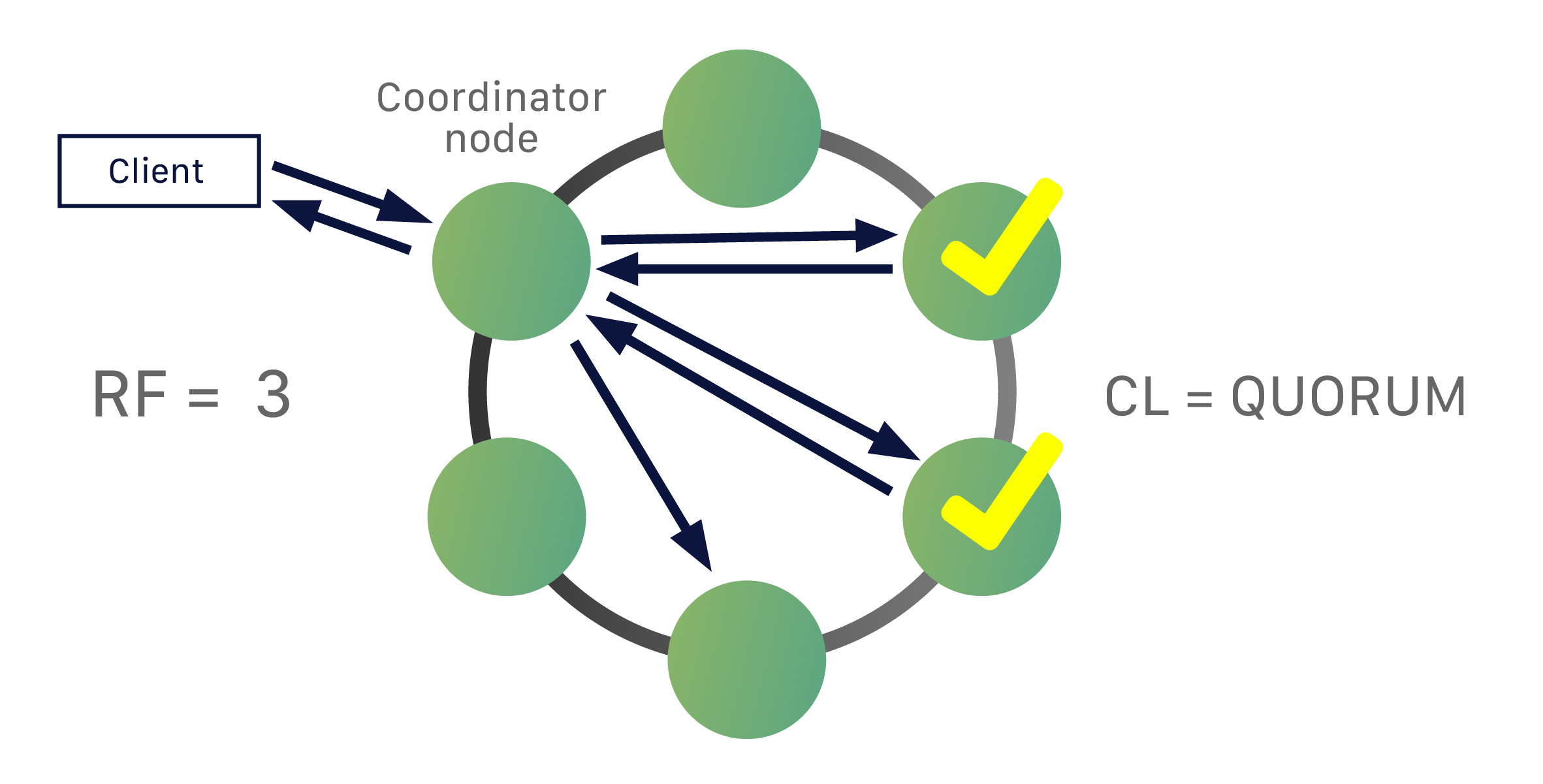
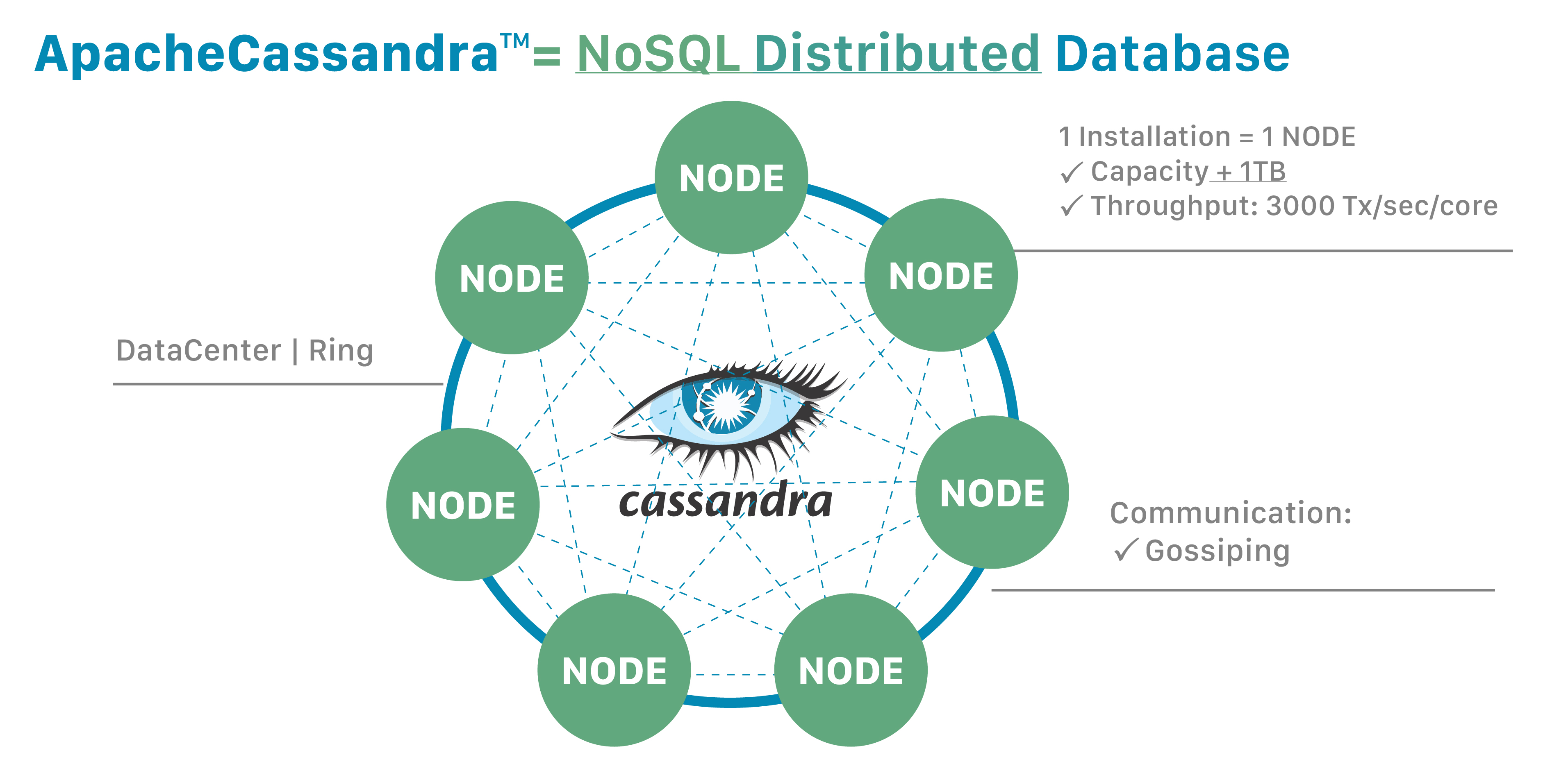
由于 Cassandra 是一个分布式数据库,因此它可以(通常也确实)拥有多个节点。节点代表 Cassandra 的单个实例。这些节点通过称为“Gossip”的协议相互通信,这是一种计算机对等通信过程。Cassandra 还具有无主架构——数据库中的任何节点都可以提供与任何其他节点完全相同的功能——这有助于提高 Cassandra 的健壮性和弹性。多个节点可以在逻辑上组织成一个集群或“环”。你还可以拥有多个数据中心。