













简介
Apache Cassandra 将数据存储在表中,每个表都包含行和列。CQL(Cassandra 查询语言)用于查询存储在表中的数据。Apache Cassandra 数据模型基于查询并针对查询进行了优化。Cassandra 不支持为关系数据库设计的关联数据建模。
什么是数据建模?
数据建模是识别实体及其关系的过程。在关系数据库中,数据被放置在规范化的表中,使用外键来引用其他表中的相关数据。应用程序将执行的查询由表的结构驱动,相关数据作为表联接进行查询。
在 Cassandra 中,数据建模是查询驱动的。数据访问模式和应用程序查询决定了数据的结构和组织方式,然后用于设计数据库表。
数据是围绕特定查询建模的。查询最好设计为访问单个表,这意味着查询中涉及的所有实体都必须在同一个表中,以使数据访问(读取)非常快。数据建模最适合查询或一组查询。一个表可以包含一个或多个实体,最适合查询。由于实体通常在它们之间存在关系,并且查询可能涉及实体之间存在关系,因此单个实体可能包含在多个表中。
查询驱动建模
与关系数据库模型不同,关系数据库模型中的查询使用表联接从多个表中获取数据,Cassandra 中不支持联接,因此所有必需的字段(列)必须分组到单个表中。由于每个查询都由一个表支持,因此数据在多个表中被复制,这个过程称为反规范化。数据复制和高写入吞吐量用于实现高读取性能。
目标
选择主键和分区键对于将数据均匀分布在集群中非常重要。将查询读取的分区数量保持在最低限度也很重要,因为不同的分区可能位于不同的节点上,协调器需要向每个节点发送请求,从而增加请求开销和延迟。即使查询中涉及的不同分区位于同一个节点上,更少的分区也能使查询更有效率。
分区
Apache Cassandra 是一个分布式数据库,它将数据存储在节点集群中。分区键用于将数据分区到节点之间。Cassandra 使用一致哈希的变体将数据分区到存储节点上,以进行数据分布。哈希是一种用于映射数据的技术,给定一个键,哈希函数会生成一个哈希值(或简称为哈希值),该哈希值存储在哈希表中。分区键是从主键的第一个字段生成的。使用分区键将数据分区到哈希表中可以实现快速查找。用于查询的分区越少,查询的响应时间就越快。
例如,考虑表 t,其中 id 是主键中唯一的字段。
CREATE TABLE t ( id int, k int, v text, PRIMARY KEY (id) );
分区键是从主键 id 生成的,用于将数据分布到集群中的节点上。
考虑表 t 的变体,它有两个字段构成主键,形成复合主键或组合主键。
CREATE TABLE t ( id int, c text, k int, v text, PRIMARY KEY (id,c) );
对于具有复合主键的表 t,第一个字段 id 用于生成分区键,第二个字段 c 是用于在分区内排序的聚类键。使用聚类键对数据进行排序可以更有效地检索相邻数据。
通常,主键的第一个字段或组件被哈希以生成分区键,其余字段或组件是用于在分区内排序的聚类键。对数据进行分区可以提高读取和写入的效率。其他不是主键字段的字段可以单独索引,以进一步提高查询性能。
如果将多个字段分组作为主键的第一个组件,则可以从多个字段生成分区键。作为表 t 的另一个变体,考虑一个表,其中主键的第一个组件由两个使用括号分组的字段组成。
CREATE TABLE t ( id1 int, id2 int, c1 text, c2 text k int, v text, PRIMARY KEY ((id1,id2),c1,c2) );
对于前面的表 t,主键的第一个组件构成字段 id1 和 id2 用于生成分区键,其余字段 c1 和 c2 是用于在分区内排序的聚类键。
与关系数据模型的比较
关系数据库将数据存储在表中,这些表使用外键与其他表建立关系。关系数据库对数据建模的方法是表为中心。查询必须使用表联接从多个具有关系的表中获取数据。Apache Cassandra 没有外键或关系完整性的概念。Apache Cassandra 的数据模型基于设计高效的查询;不涉及多个表的查询。关系数据库规范化数据以避免重复。相反,Apache Cassandra 通过在多个表中复制数据来反规范化数据,以实现以查询为中心的数据模型。如果 Cassandra 数据模型无法完全集成特定查询中不同实体之间关系的复杂性,则可以在应用程序代码中使用客户端联接。
数据建模示例
例如,magazine 数据集包含杂志数据,其属性包括杂志 ID、杂志名称、出版频率、出版日期和出版商。杂志数据的基本查询 (Q1) 是列出所有杂志名称,包括它们的出版频率。由于 Q1 不需要所有数据属性,因此数据模型将仅包含 id(用于分区键)、杂志名称和出版频率,如 图 1 所示。
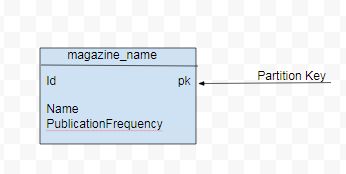
另一个查询 (Q2) 是按出版商列出所有杂志名称。对于 Q2,数据模型将包含一个额外的属性 publisher 用于分区键。id 将成为用于在分区内排序的聚类键。Q2 的数据模型如图 2 所示。
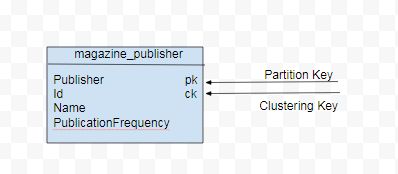
设计模式
创建概念数据模型后,可以为查询设计模式。对于 Q1,可以使用以下模式。
CREATE TABLE magazine_name (id int PRIMARY KEY, name text, publicationFrequency text)对于 Q2,模式定义将包括用于排序的聚类键。
CREATE TABLE magazine_publisher (publisher text,id int,name text, publicationFrequency text,
PRIMARY KEY (publisher, id)) WITH CLUSTERING ORDER BY (id DESC)数据模型分析
数据模型是一个概念模型,必须根据存储、容量、冗余和一致性进行分析和优化。数据模型可能需要根据分析结果进行修改。数据模型分析中使用的注意事项或限制包括
-
分区大小
-
数据冗余
-
磁盘空间
-
轻量级事务 (LWT)
分区大小的两个衡量标准是分区中的值数量和磁盘上的分区大小。虽然这些衡量标准的要求可能因应用程序而异,但一般准则是将每个分区的价值数量保持在 100,000 以下,每个分区的磁盘空间保持在 100MB 以下。
在数据模型的设计中,预计会出现数据冗余,例如表中的重复数据和多个分区副本,但无论如何,应将它们作为参数考虑,并将其保持在最低限度。LWT 事务(比较和设置、条件更新)可能会影响性能,应将使用 LWT 的查询保持在最低限度。